Символы
Содержание
- Пример 1
- Пример 2
- Управляющие последовательности
- Методы класса символов в Java
Когда мы работаем в Java с символами, мы используем примитивный тип данных char.
Пример 1
Тем не менее, в разработке, мы встречаем ситуаций, где нам нужно использовать объекты вместо примитивных типов данных. Чтобы добиться этого, Java предоставляет класс-оболочку символов для примитивных данных типа char.
В Java класс символов предлагает ряд полезных (например, static) методов для манипулирования символами. Объект символа создается с помощью символьного конструктора (Character):
Java-компилятор также создаст объект символа для Вас в некоторых обстоятельствах. Например, если примитивный тип данных char передается в метод, ожидающий объект, компилятор автоматически преобразует для Вас char в объект Character. Эта функция называется автоматическая упаковка или распаковка, если преобразование идет другим путем.
Пример 2
Управляющие последовательности
В программирование на Java символ, которому предшествует знак обратной косой черты (\), называется управляющей последовательностью и имеет особое значение для компилятора.
Символ перехода на новую строку (\n) часто используется в наших примерах в System.out.println(), оператор переносит на следующую строку после напечатанной строки.
В приведенной ниже таблице показаны управляющие последовательности, используемые в Java:
| Управляющая последовательность | Описание |
| \t | Символ табуляции. |
| \b | Символ возврата в тексте на один шаг назад или удаление одного символа в строке (backspace). |
| \n | Символ перехода на новую строку. |
| \r | Символ возврата каретки. |
| \f | Прогон страницы. |
| \’ | Символ одинарной кавычки. |
| \» | Символ двойной кавычки. |
| \\ | Символ обратной косой черты (\). |
Когда управляющая последовательность встречает оператор print, java-компилятор интерпретирует это соответственно.
Пример управляющих последовательностей
Получим следующий результат:
Пример вставки символа двойных кавычек в строку
Чтобы вставить символ двойных кавычек в строку используйте управляющую последовательность \». Если Вы хотите взять в кавычки слово или словосочетание — вставьте \» 2 раза, одну в начале, другую в конце:
Получим следующий результат:
Методы класса символов в Java
Список методов, реализующий подклассы класса символов:
| № | Методы с описанием |
| 1 | isLetter() Определяет, является ли значение указанного типа char буквой. |
| 2 | isDigit() Определяет, является ли величина указанного типа char цифрой. |
| 3 | isWhitespace() Определяет, является ли значение указанного типа char пустым пространством. |
| 4 | isUpperCase() Определяет, является ли значение указанного типа char в верхнем регистре. |
| 5 | isLowerCase() Определяет, является ли величина указанного типа char в нижнем регистре. |
| 6 | toUpperCase() Возвращает значение в верхнем регистре в виде указанного типа char. |
| 7 | toLowerCase() Возвращает значение в нижнем регистре в виде указанного типа char. |
| 8 | toString() Возвращает строковый объект, представляющий указанное символьное значение, string — один символ. |
Полный список методов Вы найдете обратившись к спецификации API java.lang.Character.
Источник
Типы данных char и String: примеры применения — введение в Java 004 #
Таблица символов
Если в программе нужны символы, то для этого мы пользуемся типом данных char. Например:
Объект базового (примитивного) типа char является 16-битным символом Unicode.
Мы можем вывести любое сообщение или любой символ. однако достаточно сложно вывести на экран кавычки, ведь в них мы и держим значения наших переменных. Для таких случаев мы используем экранирование. С помощью обратной косой черты(обратный слеш) мы экранируем символ или используем её для дополнительных параметров.
Таблица символов Windows (charmap) вызывает и показывает именно те символы, которые можно вызвать в Java.
String #
Мы можем хранить в программе и набор символов: пароль, фамилию, звание, название улицы или просто набор символов. Для хранения таких данных можно использовать String. Пример использования:
Один символ можно записать как “маленьким” стрингом, так и через символ при помощи типа данных char. Цепочку символов, больше одного, мы храним в типе данных String. Каждый элемент этой цепочки символов можно отобразить при помощи char. Это очень важно понять и запомнить.
Строковый набор символов класса String может немного больше, чем просто хранить строчку в переменной. Например, мы можем вычислить количество символов или длину String, используя один из методов, которые есть в Java. Это примерно такие же методы, как те, что мы использовали в предыдущих уроках, чтобы возводить числа в степень или выводить результаты на экран:
Для переменных типа String ява заготовила много дополнительных методов, которые делают нашу жизнь проще. Например, метод substring, который вырезает из одной цепочки символов другую.
Если мы пишем приложение для веб-сайта с “user generated content”, то мы можем столкнуться с тем, что часть контента пишется заглавными буквами. В Java есть методы, которые приводят цепочку символов алфавита к прописным (заглавным) или к строчным (маленьким) буквам. Давайте рассмотрим пример:
С помощью метода toUpperCase() мы делаем буквы прописными, с помощью метода toLowerCase() мы приводим значение строки к строчным буквам.
Мы обязательно вернёмся к этому и другим возможностям класса. Пока надо только запомнить, что, если мы хотим создать записную книжку, то фамилию и имя абонента мы скорее всего будем хранить с помощью типа данных String.
Явные и неявные преобразования #
Значения, передаваемые переменным, можно привести в тот тип данных, которые переменная может принять. Вручную или автоматически, или явно и неявно.
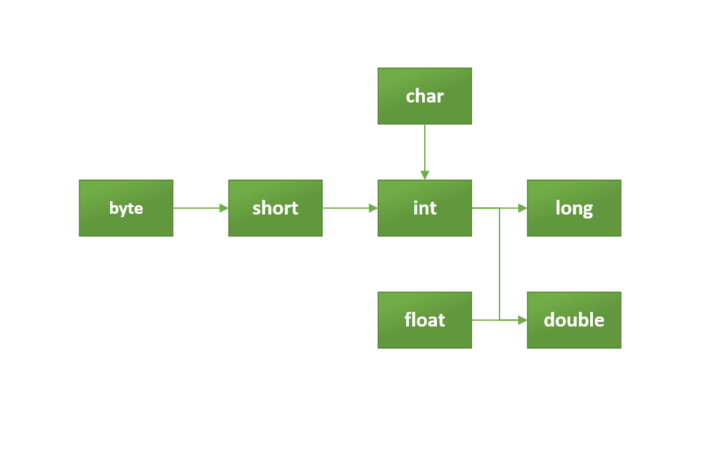
преобразование типов данных
Расширение типа (widening Casting), которое можно проследить на схеме с помощью стрелок, происходит автоматически. Это преобразование меньшего типа данных в типа большего размера: byte -> short -> char -> int -> long -> float -> double.
Сужение типа (narrowing Casting) — преобразование типа данных большего размера в тип данных меньшего размера — делается вручную: double -> float -> long -> int -> char -> short -> byte
Повышение типа на примере
Допустим, у нас имеется старая база данных, где все данные записаны в строковом виде. Например просто текстовый файл столбиком. Java даёт нам возможность “спарсить” целочисленные данные из строк.
Источник
Руководство по кодировке символов
Изучите кодировку символов в Java и узнайте о распространенных подводных камнях.
Автор: Kumar Chandrakant
Дата записи
1. Обзор
В этом уроке мы обсудим основы кодирования символов и то, как мы справляемся с этим в Java.
2. Важность кодирования символов
Нам часто приходится иметь дело с текстами, принадлежащими к нескольким языкам с различными письменными знаками, такими как латинский или арабский. Каждый символ в каждом языке должен быть каким-то образом сопоставлен с набором единиц и нулей. Действительно, удивительно, что компьютеры могут правильно обрабатывать все наши языки.
Чтобы сделать это правильно, нам нужно подумать о кодировке символов. Невыполнение этого требования часто может привести к потере данных и даже уязвимостям безопасности.
Чтобы лучше понять это, давайте определим метод декодирования текста на Java:
Обратите внимание, что вводимый здесь текст использует кодировку платформы по умолчанию.
Если мы запустим этот метод с input как “Шаблон фасада-это шаблоны проектирования программного обеспечения.” и кодировка как “US-ASCII” , он выведет:
Ну, не совсем то, что мы ожидали.
Что могло пойти не так? Мы постараемся понять и исправить это в оставшейся части этого урока.
3. Основы
Однако, прежде чем копать глубже, давайте быстро рассмотрим три термина: кодировка , кодировка и кодовая точка .
3.1. Кодирование
Компьютеры могут понимать только двоичные представления, такие как 1 и 0 . Обработка всего остального требует некоторого сопоставления текста реального мира с его двоичным представлением. Это отображение-то, что мы знаем как кодировка символов или просто как кодировка .
Например, первая буква в нашем сообщении, “T”, в US-ASCII кодирует в “01010100”.
3.2. Кодировки
Сопоставление символов с их двоичными представлениями может сильно различаться с точки зрения символов, которые они включают. Количество символов, включенных в сопоставление, может варьироваться от нескольких до всех символов, используемых на практике. Набор символов, включенных в определение отображения, формально называется кодировкой .
3.3. Кодовый пункт
Кодовая точка-это абстракция, которая отделяет символ от его фактической кодировки. A кодовая точка – это целочисленная ссылка на определенный символ.
Мы можем представить само целое число в простых десятичных или альтернативных основаниях, таких как шестнадцатеричное или восьмеричное. Мы используем альтернативные базы для удобства ссылки на большие числа.
Например, первая буква в нашем сообщении, T, в Юникоде имеет кодовую точку “U+0054” (или 84 в десятичной системе счисления).
4. Понимание Схем Кодирования
Кодировка символов может принимать различные формы в зависимости от количества символов, которые она кодирует.
Количество закодированных символов имеет прямое отношение к длине каждого представления, которое обычно измеряется как количество байтов. Наличие большего количества символов для кодирования по существу означает необходимость более длинных двоичных представлений.
Давайте рассмотрим некоторые из популярных схем кодирования на практике сегодня.
4.1. Однобайтовое кодирование
Одна из самых ранних схем кодирования, называемая ASCII (Американский стандартный код для обмена информацией), использует однобайтовую схему кодирования. По сути, это означает, что каждый символ в ASCII представлен семибитными двоичными числами. Это все еще оставляет один бит свободным в каждом байте!
Ascii 128-символьный набор охватывает английские алфавиты в нижнем и верхнем регистрах, цифры и некоторые специальные и контрольные символы.
Давайте определим простой метод в Java для отображения двоичного представления символа в определенной схеме кодирования:
Теперь символ ” T ” имеет кодовую точку 84 в US-ASCII (ASCII в Java называется US-ASCII).
И если мы используем наш метод утилиты, мы можем увидеть его двоичное представление:
Это, как мы и ожидали, семиразрядное двоичное представление символа “T”.
Исходный ASCII оставил самый значимый бит каждого байта неиспользованным. В то же время ASCII оставил довольно много непредставленных символов,
Исходный ASCII оставил самый значимый бит каждого байта неиспользованным. || В то же время ASCII оставил довольно много непредставленных символов,
Было предложено и принято несколько вариантов схемы кодирования ASCII.
Многие расширения ASCII имели разные уровни успеха, но, очевидно, это
Одним из наиболее популярных расширений ASCII был ISO-8859-1 , также называемый “ISO Latin 1”.
4.2. Многобайтовое кодирование
Поскольку потребность в размещении все большего количества символов росла, однобайтовые схемы кодирования, такие как ASCII, не были устойчивыми.
Это привело к появлению многобайтовых схем кодирования, которые имеют гораздо большую емкость, хотя и за счет увеличения требований к пространству.
BIG 5 и SHIFT-JIS являются примерами многобайтовых схем кодирования символов, которые начали использовать как один, так и два байта для представления более широких наборов символов . Большинство из них были созданы для того, чтобы представлять китайские и аналогичные сценарии, которые имеют значительно большее количество символов.
Давайте теперь вызовем метод convertToBinary с вводом как “語”, китайский символ, и кодирование как “Big5”:
Вывод выше показывает, что кодировка Big5 использует два байта для представления символа “語”.
полный список кодировок символов, наряду с их псевдонимами, ведется Международным органом по номерам.
5. Юникод
Нетрудно понять, что, хотя кодирование важно, декодирование в равной степени жизненно важно для понимания представлений. Это возможно на практике только в том случае, если широко используется согласованная или совместимая схема кодирования.
Различные схемы кодирования, разработанные изолированно и практикуемые в местных географических регионах, начали становиться сложными.
Эта проблема породила особый стандарт кодирования, называемый Unicode, который имеет емкость для всех возможных символов в мире . Это включает в себя символы, которые используются, и даже те, которые уже не существуют!
Ну, для этого должно потребоваться несколько байтов для хранения каждого символа? Честно говоря, да, но у Unicode есть гениальное решение.
Unicode как стандарт определяет кодовые точки для каждого возможного символа в мире. Кодовая точка для символа “T” в Юникоде равна 84 в десятичной системе счисления. Обычно мы называем это “U+0054” в Юникоде, который представляет собой не что иное, как U+, за которым следует шестнадцатеричное число.
Мы используем шестнадцатеричную систему в качестве основы для кодовых точек в Юникоде, поскольку существует 1 114 112 точек, что является довольно большим числом для удобной передачи в десятичном формате!
То, как эти кодовые точки кодируются в биты, зависит от конкретных схем кодирования в Юникоде. Мы рассмотрим некоторые из этих схем кодирования в подразделах ниже.
5.1. UTF-32
UTF-32-это схема кодирования для Unicode, которая использует четыре байта для представления каждой кодовой точки , определенной Unicode. Очевидно, что использование четырех байтов для каждого символа неэффективно.
Давайте посмотрим, как простой символ, такой как “T”, представлен в UTF-32. Мы будем использовать метод преобразования в двоичный код , введенный ранее:
Вывод выше показывает использование четырех байтов для представления символа “T”, где первые три байта-это просто потраченное впустую пространство.
5.2. UTF-8
UTF-8-это другая схема кодирования для Unicode, которая использует переменную длину байтов для кодирования . Хотя он обычно использует один байт для кодирования символов, при необходимости он может использовать большее количество байтов, что экономит место.
Давайте снова вызовем метод convertToBinary с вводом как “T” и кодированием как ” UTF-8″:
Вывод в точности аналогичен ASCII, использующему только один байт. На самом деле UTF-8 полностью обратно совместим с ASCII.
Давайте снова вызовем метод convertToBinary с вводом как “語” и кодированием как ” UTF-8″:
Как мы видим здесь, UTF-8 использует три байта для представления символа “語”. Это известно как кодирование переменной ширины .
UTF-8, благодаря своей экономичности пространства, является наиболее распространенной кодировкой, используемой в Интернете.
6. Поддержка кодирования в Java
Java поддерживает широкий спектр кодировок и их преобразования друг в друга. Класс Charset определяет набор стандартных кодировок , которые должна поддерживать каждая реализация платформы Java.
Это включает в себя US-ASCII, ISO-8859-1, UTF-8 и UTF-16, чтобы назвать некоторые из них. Конкретная реализация Java может дополнительно поддерживать дополнительные кодировки .
Есть некоторые тонкости в том, как Java подбирает кодировку для работы. Давайте рассмотрим их более подробно.
6.1. Кодировка по умолчанию
Платформа Java сильно зависит от свойства, называемого кодировкой по умолчанию . Виртуальная машина Java (JVM) определяет кодировку по умолчанию во время запуска .
Это зависит от локали и кодировки базовой операционной системы, на которой работает JVM. Например, в macOS кодировка по умолчанию-UTF-8.
Давайте посмотрим, как мы можем определить кодировку по умолчанию:
Если мы запустим этот фрагмент кода на компьютере с Windows, то получим результат:
Теперь “windows-1252” – это кодировка по умолчанию платформы Windows на английском языке, которая в данном случае определила кодировку по умолчанию JVM, работающей в Windows.
6.2. Кто использует Кодировку по умолчанию?
Многие API Java используют кодировку по умолчанию, определенную JVM. Чтобы назвать несколько:
- InputStreamReader и Средство чтения файлов
- OutputStreamWriter и Файловая машина
- Форматер и Сканер
- URLEncoder и URLDecoder
Итак, это означает, что если бы мы запустили наш пример без указания кодировки:
затем он будет использовать кодировку по умолчанию для ее декодирования.
И есть несколько API, которые делают этот же выбор по умолчанию.
Таким образом, кодировка по умолчанию приобретает важность, которую мы не можем безопасно игнорировать.
6.3. Проблемы С Набором Символов По Умолчанию
Как мы уже видели, кодировка по умолчанию в Java определяется динамически при запуске JVM. Это делает платформу менее надежной или подверженной ошибкам при использовании в разных операционных системах.
Например, если мы запустим
в macOS он будет использовать UTF-8.
Если мы попробуем тот же фрагмент кода в Windows, он будет использовать Windows-1252 для декодирования того же текста.
Или представьте, что вы пишете файл в mac OS, а затем читаете тот же файл в Windows.
Нетрудно понять, что из-за различных схем кодирования это может привести к потере или повреждению данных.
6.4. Можем ли мы переопределить кодировку по умолчанию?
Определение кодировки по умолчанию в Java приводит к двум системным свойствам:
- file.encoding : Значение этого системного свойства является именем набора символов по умолчанию
- sun.jnu.encoding : Значением этого системного свойства является имя набора символов, используемого при кодировании/декодировании путей к файлам
Теперь интуитивно понятно переопределять эти системные свойства с помощью аргументов командной строки:
Однако важно отметить, что эти свойства доступны только для чтения в Java. Их использование, как указано выше, отсутствует в документации . Переопределение этих системных свойств может не иметь желаемого или предсказуемого поведения.
Следовательно, мы должны избегать переопределения кодировки по умолчанию в Java .
6.5. Почему Java Не Решает Эту Проблему?
Существует предложение по улучшению Java (JEP), которое предписывает использовать “UTF-8” в качестве кодировки по умолчанию в Java вместо того, чтобы основывать ее на кодировке локали и операционной системы.
Этот ДЖИП находится в состоянии проекта на данный момент и когда он (надеюсь!) пройдя через него, мы решим большинство вопросов, которые мы обсуждали ранее.
Обратите внимание, что более новые API, такие как в файле java.nio.file.Файлы не используют кодировку по умолчанию. Методы в этих API-интерфейсах читают или записывают символьные потоки с кодировкой UTF-8, а не с кодировкой по умолчанию.
6.6. Решение Этой Проблемы в Наших Программах
Обычно мы должны выбирать кодировку при работе с текстом, а не полагаться на настройки по умолчанию . Мы можем явно объявить кодировку, которую мы хотим использовать в классах, которые имеют дело с преобразованием символов в байты.
К счастью, наш пример уже определяет кодировку. Нам просто нужно выбрать правильный, и пусть Java сделает все остальное.
К настоящему времени мы должны понять, что акцентированные символы, такие как “ç”, отсутствуют в схеме кодирования ASCII, и поэтому нам нужна кодировка, которая включает их. Может быть, UTF-8?
Давайте попробуем это сделать, теперь мы запустим метод decode Text с тем же вводом, но с кодировкой “UTF-8”:
Бинго! Мы можем увидеть результат, который мы надеялись увидеть.
Здесь мы установили кодировку, которая, по нашему мнению, лучше всего соответствует нашим потребностям в конструкторе InputStreamReader . Обычно это самый безопасный метод работы с символами и преобразованиями байтов в Java.
Аналогично, OutputStreamWriter и многие другие API поддерживают настройку схемы кодирования через свой конструктор.
6.7. Исключение MalformedInputException
Когда мы декодируем последовательность байтов, существуют случаи , когда она не является законной для данной кодировки , или же это не является законным шестнадцатибитным Юникодом. Другими словами, данная последовательность байтов не имеет отображения в указанной кодировке .
Существует три предопределенные стратегии (или CodingErrorAction ), когда входная последовательность имеет искаженные входные данные:
- ИГНОРИРОВАТЬ будет игнорировать искаженные символы и возобновит операцию кодирования
- REPLACE заменит искаженные символы в выходном буфере и возобновит операцию кодирования
- ОТЧЕТ вызовет исключение MalformedInputException
По умолчанию malformedInputAction для кодера CharsetDecoder является REPORT, и по умолчанию malformedInputAction декодера по умолчанию в InputStreamReader is REPLACE.
Давайте определим функцию декодирования , которая получает заданную кодировку , тип CodingErrorAction и строку, подлежащую декодированию:
Итак, если мы решим, что “Шаблон фасада-это шаблон проектирования программного обеспечения.” с помощью US_ASCII выходные данные для каждой стратегии будут разными. Во-первых, мы используем CodingErrorAction.ИГНОРИРОВАТЬ , который пропускает недопустимые символы:
Для второго теста мы используем CodingErrorAction.ЗАМЕНИТЕ , который помещает � вместо запрещенных символов:
Для третьего теста мы используем CodingErrorAction.ОТЧЕТ который приводит к выбрасыванию MalformedInputException:
7. Другие Места, Где Кодирование Важно
Нам не просто нужно учитывать кодировку символов при программировании. Тексты могут окончательно испортиться во многих других местах.
наиболее распространенной причиной проблем в этих случаях является преобразование текста из одной схемы кодирования в другую , что может привести к потере данных.
Давайте быстро рассмотрим несколько мест, где мы можем столкнуться с проблемами при кодировании или декодировании текста.
7.1. Текстовые Редакторы
В большинстве случаев текстовый редактор-это место, откуда исходят тексты. Существует множество текстовых редакторов в популярном выборе, включая vi, Блокнот и MS Word. Большинство из этих текстовых редакторов позволяют нам выбрать схему кодирования. Следовательно, мы всегда должны быть уверены, что они подходят для текста, с которым мы работаем.
7.2. Файловая система
После того, как мы создадим тексты в редакторе, нам нужно сохранить их в какой-то файловой системе. Файловая система зависит от операционной системы, на которой она работает. Большинство операционных систем имеют встроенную поддержку нескольких схем кодирования. Однако все еще могут быть случаи, когда преобразование кодировки приводит к потере данных.
7.3. Сеть
Тексты, передаваемые по сети с использованием протокола, такого как протокол передачи файлов (FTP), также включают преобразование между кодировками символов. Для всего, что закодировано в Юникоде, безопаснее всего передавать в двоичном виде, чтобы свести к минимуму риск потери при преобразовании. Однако передача текста по сети является одной из менее частых причин повреждения данных.
7.4. Базы данных
Большинство популярных баз данных, таких как Oracle и MySQL, поддерживают выбор схемы кодирования символов при установке или создании баз данных. Мы должны выбрать это в соответствии с текстами, которые мы ожидаем сохранить в базе данных. Это одно из наиболее частых мест, где повреждение текстовых данных происходит из-за преобразования кодировки.
7.5. Браузеры
Наконец, в большинстве веб-приложений мы создаем тексты и пропускаем их через различные слои с намерением просмотреть их в пользовательском интерфейсе, например в браузере. Здесь также важно, чтобы мы выбрали правильную кодировку символов, которая может правильно отображать символы. Большинство популярных браузеров, таких как Chrome, Edge, позволяют выбирать кодировку символов в своих настройках.
8. Заключение
В этой статье мы обсудили, как кодирование может быть проблемой при программировании.
Далее мы обсудили основные принципы, включая кодировку и кодировки. Более того, мы прошли через различные схемы кодирования и их использование.
Мы также подобрали пример неправильного использования кодировки символов в Java и увидели, как это сделать правильно. Наконец, мы обсудили некоторые другие распространенные сценарии ошибок, связанные с кодировкой символов.
Как всегда, код для примеров доступен на GitHub .
Источник
Очень странные вещи c Java Characters
Тайна ошибки комментария и другие истории.

Вступление
Знаете ли вы, что следующее является допустимым выражением Java?
Вы можете попробовать скопировать и вставить его в основной метод любого класса и скомпилировать. Если вы затем добавите следующий оператор
и после компиляции запустите этот класс, код напечатает число 8!
А знаете ли вы, что этот комментарий вместо этого вызывает синтаксическую ошибку во время компиляции?
Тем не менее, комментарии не должны приводить к синтаксическим ошибкам. Фактически, программисты часто комментируют фрагменты кода, чтобы компилятор их игнорировал. так что же происходит?
Для того, чтобы узнать почему это происходит, потратьте несколько минут на небольшой обзор основ Java о примитивном типе char .
Примитивный тип данных char
Как всем известно, char это один из восьми примитивных типов Java. Это позволяет нам хранить по одному символу. Ниже приведен простой пример, в котором значение символа присваивается типу char :
На самом деле этот тип данных используется нечасто, потому что в большинстве случаев программистам нужны последовательности символов и поэтому они предпочитают строки. Каждое буквальное значение символа должно быть заключено между двумя одинарными кавычками, чтобы не путать с двойными кавычками, используемыми для строковых литералов. Объявление строки:
Есть три способа присвоить литералу значение типа char , и все три требуют включения значения в одинарные кавычки:
используя один печатный символ на клавиатуре (например ‘&’ ).
используя формат Unicode с шестнадцатеричной нотацией (например, ‘\u0061’ , который эквивалентен десятичному числу 97 и идентифицирует символ ‘a’ ).
используя специальный escape-символ (например, ‘\n’ который указывает символ перевода строки).
Давайте добавим некоторые детали в следующих трех разделах.
Печатаемые символы клавиатуры
Мы можем назначить любой символ, найденный на нашей клавиатуре, char переменной, при условии, что наши системные настройки поддерживают требуемый символ и что этот символ доступен для печати (например, клавиши «Canc» и «Enter» не печатаются).
В любом случае литерал, присваиваемый примитивному типу char , всегда заключен между двумя одинарными кавычками. Вот некоторые примеры:
Тип данных char хранится в 2 байтах (16 бит), а диапазон состоит только из положительных чисел от 0 до 65 535. Фактически, существует «отображение», которое связывает определенный символ с каждым числом. Это отображение (или кодирование) определяется стандартом Unicode (более подробно описанным в следующем разделе).
Формат Unicode (шестнадцатеричное представление)
Мы сказали, что примитивный тип char хранится в 16 битах и может определять до 65 536 различных символов. Кодирование Unicode занимается стандартизацией всех символов (а также символов, смайликов, идеограмм и т. д.), существующих на этой планете. Unicode — это расширение кодировки, известной как UTF-8, которая, в свою очередь, основана на старом 8-битном расширенном стандарте ASCII, который, в свою очередь, содержит самый старый стандарт, ASCII code (аббревиатура от American Standard Code for Information Interchange).
Мы можем напрямую присвоить Unicode char значение в шестнадцатеричном формате, используя 4 цифры, которые однозначно идентифицируют данный символ, добавляя к нему префикс \u (всегда в нижнем регистре). Например:
В данном случае мы говорим о литерале в формате Unicode (или литерале в шестнадцатеричном формате). Фактически, при использовании 4 цифр в шестнадцатеричном формате охватывается ровно 65 536 символов.
Java 15 поддерживает Unicode версии 13.0, которая содержит намного больше символов, чем 65 536 символов. Сегодня стандарт Unicode сильно изменился и теперь позволяет нам представлять потенциально более миллиона символов, хотя уже присвоено только 143 859 чисел конкретным символам. Но стандарт постоянно развивается. В любом случае, для присвоения значений Unicode, выходящих за пределы 16-битного диапазона типа char , мы обычно используем классы вроде String и Character , но поскольку это очень редкий случай и не интересен для целей этой статьи, мы не будем об этом говорить.
Специальные escape-символы
В char типе также можно хранить специальные escape-символы, то есть последовательности символов, которые вызывают определенное поведение при печати:
\b эквивалентно backspace, отмене слева (эквивалентно клавише Delete).
\n эквивалентно переводу строки (эквивалентно клавише Ente).
\\ равняется только одному \ (только потому, что символ \ используется для escape-символов).
\t эквивалентно горизонтальной табуляции (эквивалентно клавише TAB).
\’ эквивалентно одинарной кавычке (одинарная кавычка ограничивает литерал символа).
\» эквивалентно двойной кавычке (двойная кавычка ограничивает литерал строки).
\r представляет собой возврат каретки (специальный символ, который перемещает курсор в начало строки).
\f представляет собой подачу страницы (неиспользуемый специальный символ, представляющий курсор, перемещающийся на следующую страницу документа).
Обратите внимание, что присвоение литерала ‘»‘ символу совершенно законно, поэтому следующий оператор:
что эквивалентно следующему коду:
правильно и напечатает символ двойной кавычки:
Если бы мы попытались не использовать escape-символ для одиночных кавычек, например, со следующим утверждением:
мы получим следующие ошибки времени компиляции, поскольку компилятор не сможет различить разделители символов:
Поскольку разделители строковых литералов представлены в двойных кавычках, ситуация обратная. Фактически, внутри строки можно заключить одинарные кавычки:
С другой стороны, мы должны использовать \» escape-символ, чтобы использовать двойные кавычки в строке. Итак, следующее утверждение:
вызовет следующие ошибки компиляции:
Вместо этого верна следующая инструкция:
Написание Java кода в формате Unicode
Литеральный формат Unicode также можно использовать для замены любой строки нашего кода. Фактически, компилятор сначала преобразует формат Unicode в символ, а затем оценивает синтаксис. Например, мы могли бы переписать следующий оператор:
Фактически, если мы добавим к предыдущей строке следующий оператор:
Несомненно, это бесполезный способ написания нашего кода. Но может быть полезно знать эту функцию, поскольку она позволяет нам понять некоторые ошибки, которые (редко) случаются.
Формат Unicode для escape-символов
Тот факт, что компилятор преобразует шестнадцатеричный формат Unicode перед оценкой кода, имеет некоторые последствия и оправдывает существование escape-символов. Например, давайте рассмотрим символ перевода строки, который можно представить с помощью escape-символа \n . Теоретически перевод строки связан в кодировке Unicode с десятичным числом 10 (что соответствует шестнадцатеричному числу A). Но, если мы попытаемся определить его в формате Unicode:
мы получим следующую ошибку времени компиляции:
В реальности, компилятор преобразует предыдущий код в следующий перед его оценкой:
Формат Unicode был преобразован в символ новой строки, и предыдущий синтаксис не является допустимым синтаксисом для компилятора Java.
Аналогично, символ одинарной кавычки ‘ , который соответствует десятичному числу 39 (эквивалентно шестнадцатеричному числу 27) и который мы можем представить с помощью escape-символа \’, не может быть представлен в формате Unicode:
Также в этом случае компилятор преобразует предыдущий код следующим образом:
что приведет к следующим ошибкам времени компиляции:
Первая ошибка связана с тем, что первая пара кавычек не содержит символа, а вторая ошибка указывает на то, что указание третьей одинарной кавычки является незакрытым символьным литералом.
Также есть проблемы с символом возврата каретки, представленным шестнадцатеричным числом D (соответствующим десятичному числу 13) и уже представленным с помощью escape-символа \r . Фактически, если мы напишем:
мы получим следующую ошибку времени компиляции:
Фактически, компилятор преобразовал число в формате Unicode в возврат каретки, вернув курсор в начало строки, и то, что должно было быть второй одинарной кавычкой, стало первой.
Что касается символа , , представленного десятичным числом 92 (соответствующего шестнадцатеричному числу 5C) и представленного escape-символом \ , если мы напишем:
мы получим следующую ошибку времени компиляции:
Это потому, что предыдущий код будет преобразован в следующий:
и поэтому пара символов ‘ рассматривается как escape-символ, соответствующий одинарной кавычке, и поэтому в буквальном закрытии отсутствует другая одинарная кавычка.
С другой стороны, если мы рассмотрим символ » , представленный шестнадцатеричным числом 22 (соответствующий десятичному числу 34) и представленный escape-символом » , если мы напишем:
проблем не будет. Но если мы используем этот символ внутри строки:
мы получим следующую ошибку времени компиляции:
поскольку предыдущий код будет преобразован в следующий:
Тайна ошибки комментария
Еще более странная ситуация возникает при использовании однострочных комментариев для форматов Unicode, таких как возврат каретки или перевод строки. Например, несмотря на то, что оба следующих оператора закомментированы, могут возникнуть ошибки во время компиляции!
Это связано с тем, что компилятор всегда преобразует шестнадцатеричные форматы с помощью символов перевода строки и возврата каретки, которые несовместимы с однострочными комментариями; они печатают символы вне комментария!
Чтобы разрешить ситуацию, используйте обозначение многострочного комментария, например:
Другая ошибка, из-за которой программист может потерять много времени, — это использование последовательности \u в комментарии. Например, со следующим комментарием мы получим ошибку времени компиляции:
Если компилятор не находит допустимую последовательность из 4 шестнадцатеричных символов после \u , он выведет следующую ошибку:
Выводы
В этой статье мы увидели, что использование типа char в Java скрывает некоторые действительно удивительные особые случаи. В частности, мы увидели, что можно писать код Java, используя формат Unicode. Это связано с тем, что компилятор сначала преобразует формат Unicode в символ, а затем оценивает синтаксис. Это означает, что программисты могут находить синтаксические ошибки там, где они никогда не ожидали, особенно в комментариях.
Примечание автора: эта статья представляет собой короткий отрывок из раздела 3.3.5 «Примитивные символьные типы данных» тома 1 моей книги «Java для пришельцев». Для получения дополнительной информации посетите сайт книги (вы можете загрузить раздел 3.3.5 из области «Примеры»).
Источник